When we work in virtualized worlds with Microsoft Hyper-V, there are no many things we have to worry about when it comes to processors. Most of these things come with acronyms which people don’t really understand but they know they need and these and one of these is NUMA Spanning which I’m going to try and explain here and convey why we want to avoid NUMA Spanning where possible and I’m going to do it all in fairly simple terms to keep the topic light. In reality, NUMA architectures may be more complex than this.
NUMA Spanning or Non-Uniform Memory Address Spanning was a feature introduced into motherboard chipsets by Intel and AMD. Intel implemented it with the feature set Quick Path Interconnect (QPI) in 2007 and AMD implemented it with HyperTransport in 2003. NUMA uses a construct of nodes in it’s architecture. As the name suggests, NUMA refers to system memory (RAM) and how we use memory and more specifically, how we determine which memory in the system to use.
Single NUMA Node

In the most simple system, you have a single NUMA node. A single NUMA node is achieved either in a system with a single socket processor or by using a motherboard and processor combination which does not support the concept of NUMA. With a single NUMA node, all memory is treated as equal and a VM running on a hypervisor on this configuration system would use any memory available to it without preference.
Multiple NUMA Nodes

In a typical system that we see today with multiple processor sockets and with a processor and motherboard configuration that supports NUMA, we have multiple NUMA nodes. NUMA nodes are determined by the arrangement of memory DIMMs in relation to the processor sockets on the motherboard. In a hugely oversimplified sample system with two CPU sockets, each loaded up with a single core processor and 6 DIMMs per socket, each DIMM slot populated with an 8GB DIMM (12 DIMMs total). In this configuration we have two NUMA nodes, and in each NUMA node, we have one CPU socket and it’s directly connected 48GB of memory.
The reason for this relates to the memory controller within the processor and the interconnect paths on the motherboard. The Intel Xeon processor for example has an integrated memory controller. This memory controller is responsible for the address and resource management of the six DIMMs attached to the six DIMM slots on the motherboard linked to this processor socket. For this processor to access this memory it takes the quickest possible path, directly between the processor and the memory and this is referred to as Uniform Memory Access.
For this processor to access memory that is in a DIMM slot that is linked to our second processor socket, it has to cross the interconnect on the motherboard and via the memory controller on the second CPU. All of this takes mere nanoseconds to perform but it is additional latency that we want to avoid in order to achieve maximum system performance. We also need to remember that if we have a good virtual machine consolidation ratio on our physical host, this may be happening for multiple VMs all over the place and that adds up to lots of nanoseconds all of the time. This is NUMA Spanning at work. The processor is breaking out of its own NUMA node to access Non-Uniform Memory in another NUMA node.
Considerations for NUMA Spanning and VM Sizing
NUMA Spanning has a bearing on how we should be sizing our VMs that we deploy to our Hyper-V hosts. In my sample server configuration above, I have 48GB of memory per NUMA node. To minimize the chances of VMs spanning these NUMA nodes, we therefore need to deploy our VMs with sizing considerations linked to this. If I deployed 23 VMs with 4GB of memory each, that equals 92GB. This would mean 48GB memory in the first NUMA node could be totally allocated for VM workload and 44GB of memory allocated to VMs in the second NUMA node leaving 4GB of memory for the parent partition of Hyper-V to operate in. None of these VMs would span NUMA nodes because 48GB/4GB is 12 which means 12 entire VMs can fit per NUMA node.
If I deployed 20 VMs but this time with 4.5GB of memory each, this would require 90GB memory for virtual workloads and leave 6GB for hosting the parent partition of Hyper-V. The problem here is that 48GB/4.5GB doesn’t fit, we have left overs and uneven numbers. 10 of our VMs would fit entirely into the first NUMA node and 9 of our VMs would fit entirely within the second NUMA node but our 20th VM would be in no man’s land and would be left to have half its memory in both of the NUMA nodes.
In good design practice, we should try to size our VMs to match our NUMA architecture. Take my sample server configuration of 48GB per NUMA node, we should use VMs with memory sizes of either 2GB, 4GB, 6GB, 8GB, 12GB, 24GB or 48GB. Anything other than this has a real risk to be NUMA spanned.
Considerations for Disabling NUMA Spanning
So now that we understand what NUMA Spanning is and the potential decrease in performance it can cause, we need to look at it with a virtualization lens as this is where it really takes effect to the maximum. The hypervisor understands the NUMA architecture of the host through the detection of the hardware within. When a VM tries to start and the hypervisor attempts to allocate memory for the VM, it will always try to first get memory within the NUMA node for the processor that is being used for the virtual workload but sometimes that may not be possible due to other workloads blocking the memory.
For the most part, leaving NUMA Spanning enabled is totally fine but if you are really trying to squeeze performance from a system, a virtual SQL Server perhaps, NUMA Spanning would be something we would like to have turned off. NUMA Spanning is enabled by default in both VMware and Hyper-V and it is enabled at the host level but we can override this configuration on both a per hypervisor host level and a per VM level.
I am not for one minute going to recommend that you disable NUMA Spanning at the host level as this might impact your ability to run your workloads. If NUMA Spanning is disabled for the host and the host is not able to accommodate the memory demand of the VM within a single NUMA node, the power on request for the VM will fail and you will be unable to turn on the machine however if you have some VMs which have NUMA Spanning disabled and others with it enabled, you can have your host work like a memory based jigsaw puzzle, fitting things in where it can.
Having SQL Servers and performance sensitive VMs running with NUMA Spanning disabled would be advantageous to their performance and having NUMA Spanning disabled on VMs which are not performance sensitive allows them to use whatever memory is available and cross NUMA nodes as required giving you the best combination of maximum performance for your intensive workloads and the resources required to run those that are not.
Using VMM Hardware Profiles to Manage NUMA Spanning
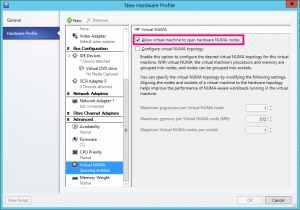
So assuming we have a Hyper-V environment that is managed by Virtual Machine Manager (VMM), we can make this really easy to manage without having to bother our users or systems administrators with understanding NUMA Spanning. When we deploy VMs we can base our VMs on Hardware Profiles. A VMM Hardware Profile has the NUMA Spanning option available to us and simply, we would create multiple Hardware Profiles for our workload types, some of which would be for general purpose servers with NUMA Spanning enabled whilst other Hardware Profiles would be configured specifically to be used by performance sensitive workloads with the NUMA Spanning setting disabled in the profile.
The key to remember here is that if you have VMs that are already deployed in your environment you will need to update their configuration. Hardware Profiles in VMM are not linked to the VMs that we deploy so once a VM is deployed, any changes to the Hardware Profile that it was deployed from do not filter down to the VM. The other thing to note is that NUMA Spanning configuration is only applied at VM Startup and during Live or Quick Migration. If you want your VMs to update the NUMA Spanning configuration after you have changed the setting you will either need to stop and start the VM or migrate it to another host in your Hyper-V Failover Cluster.