Project Home Lab: Server Surgery Aftermath
So it seems that in my last post about relocating the Home Server into the new chassis was spoken a little too soon. Over New Year, a few days after the post, I started to have some problems with the machine.
It first happened when I removed the 3TB drive from the chassis to replace it with the new 5TB drive which caused a Storage Spaces rebuild and all of the drives started to chatter away copying blocks around and about half-way through the rebuild, the server stopped responding to pings. I jumped on to the IPMI remote console expecting to see that I was using so much I/O on the rebuild that it had decided to stop responding on the network but in actual fact, the screen was blank and there was nothing there. I tried to start a graceful shutdown using the IMPI but that failed to I had to reset the server.
When Windows came back up, it greeted me with the unexpected shutdown error. I checked Storage Spaces and the rebuild had resumed with no lost data or drives and eventually (there’s a lot of data there) it completed and I thought nothing more of it all until New Years day when the same thing happened again. This time, after restarting the server and realising this was no one off event, I changed the Startup and Recovery settings in Windows to generate a Small Memory Dump (256KB) otherwise known as a Minidump and I also disabled the automatic restart option as I wanted to try and get a chance to see the Blue Screen of Death (BSOD) if there was one.
Nothing happened on this front until yesterday. The server hung again and I restarted it but within two minutes of hanging, it did the same thing again. I decided to leave the server off for about five minutes to give it a little rest and then power it back up and since then I’ve had no issues but I have gathered a lot of data and information in the time wisely.
I used WinDbg from the Windows Debugging Tools in the Windows SDK to read the Minidump file and the resultant fault code was WHEA Uncorrectable Error with a code of 0x124. To my sadness, this appears to be one of the most vague error messages in the whole of Windows. This code means that a hardware fault occurred which Windows could not recover from but because the CPU is the last device to be seen before the crash, it looks as if the fault is coming from the CPU. The stack trace includes four arguments for the fault code and the first argument is meant to contain the ID of the device which was seen by the CPU to have faulted but you guessed it, it doesn’t.
So knowing that I’ve got something wierd going on with my hardware, I considered the possibilities. The machine is using a new motherboard so I don’t suspect that initially. It’s using a used processor and memory from eBay which are suspects one and two and it’s using the LSI MegaRAID controller from my existing build. The controller is a suspect due to the fact that on each occasion the crash has occurred, there has been a relative amount of disk I/O taking place (Storage Spaces rebuild the first time and multiple Plex Media Server streams taking place on the other occasions).
The Basic Tests
First and foremost, I checked against Windows Update and all of my patches are in order which I already knew but wanted to verify. Next, I checked my drivers as a faulting driver could cause something bad to get to the hardware and generate the fault. All of the components in the system are using WHQL signed drivers from Microsoft which have come down through Windows Update except for the RAID Controller. I checked the LSI website and there was a newer version of the LSI MegaRAID driver for my 9280-16i4e card available as well as a new version of the MegaRAID Storage Manager application so I applied both of these requiring a restart.
I checked the Intel website for drivers for both the Intel 82576 network adapters in the server and the Intel 5500 chipset and even though the version number of the Intel drivers is higher than those from Windows Update, the release date on the Windows Update drivers is later so upon trying to install them, Windows insists that the drivers installed are the best available so I’ll leave these be and won’t try to force drivers into the system.
Next up, I released that the on-board Supermicro SMC2008 SAS controller (an OEM embedded version of the LSI SAS2008 IR chipset) was enabled. I’m not using this controller and don’t have any SAS channels connected to it so I’ve disabled the device in Windows to stop it from loading for now but eventually I will open the chassis and change the pin jumper to physically disable the controller.
Earlier, I mentioned that I consider the LSI controller to be a suspect. The reason for this is not reliability of any kind as the controller is amazing and frankly beyond what I need for simple RAID0 and RAID1 virtual drives but because it is a very powerful card, it requires a lot of cooling. LSI recommend a minimum of 200 Cubic Feet per Minute (CFM) of cooling on this card and with the new chassis I have, the fans are variably controlled by the CPU temperature. Because I have the L5630 low power CPU with four cores, the CPU is not busy in the slightest on this server and as a result, the fan speed stays low.
According to the IPMI sensors, the fan speed is at 900 RPM constant with the currently system and CPU temperatures. The RAID controller is intentionally installed in the furthest possible PCI Express 8x slot from the CPU to ensure that heat is not bled from one device into the other but a byproduct of this is that the heat on the controller is likely not causing a fan speed increase. Using the BIOS, I have changed the fan configuration from the default setting of most efficient which has a minimum speed of 900 RPM to the Better Cooling option which increases the lower limit to 1350 RPM.
Lastly, I raised a support incident with LSI to confirm if there is a way to monitor the processor temperature on the controller however they have informed me that only the more modern dual core architecture controllers have the ability to see the processor temperature either via the WebBIOS or via the MSM application. If I have more problems going forwards, I have a USB temperature probe which I could temporarily install in the chassis but this isn’t going to be wholely accurate however in the meantime, the support engineer at LSI has taken an LSIGET dump of all of the controller and system data and is going to report back to me if there are any problems he can see.
The Burn Tests
Because I don’t want reliability problems on-going, I want to drive the server to crash under my own schedule and see the problems happening in live so that I can try and resolve them, I decided to perform some burn tests.
Memory Testing
Memory corruption and issues with memory is a common cause of BSODs in any system. I am using ECC buffered DIMMs can can correct memory bit errors automatically but that doesn’t mean we want them still so I decided to do a run on Memtest86.
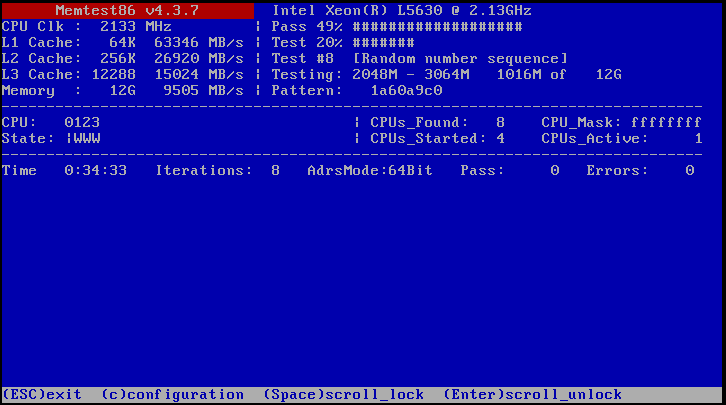
I left this running for longer than the screenshot shows, but as you can see, there are no reported errors in Memtest86 so the memory looks clear of blame. What I really like about these results is that it shows you have incredibly fast the L1 and L2 caches are on the processor and I’m even quite impressed with how fast the DDR3-10600R memory in the DIMMs themselves are.
CPU Testing
For this test, I used a combination of Prim95 and Real Temp to both make the CPU hurt and also to allow me to monitor the temperatures vs. the Max TDP of the processor. I left the test running for over an hour, 100% usage on all four physical cores and here’s the results.
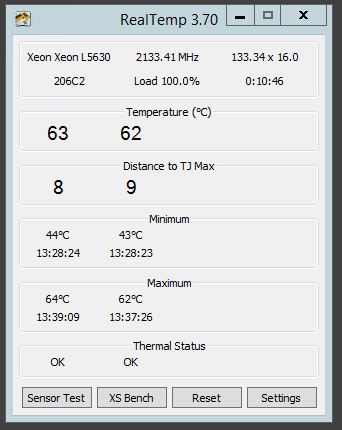
As you can see, the highest the temperature got was 63 degrees Celsius which is 9 degrees short of the Max TDP of the processor. When I log in to the server normally when there are multiple Plex Media Server transcoding sessions occurring the CPU isn’t as utilized as heavily as this test so the fact that it can run at full load and the cooling is sufficient to keep it below Max TDP makes me happy. As a result of the CPU workload, the fan speed was automatically raised by the chassis. Here’s a screenshot of the IPMI Sensor output for both the system temperatures and the fan speed, remembering that the normal speed is 1350 RPM after my change.
![]()

To my suprise, the system temperature is actually lower under the load than it is at idle. The increased airflow from the fans at the higher RPM is pushing so much air that it’s able to cool the system to two degrees below the normal idle temperature, neither of which are high by any stretch of the imagination.
Storage I/O Testing
With all of the tests thus far causing me no concern, I was worried about this one. I used ioMeter to test the storage and because ioMeter will fill a volume with a working file to undertake the tests, I created a temporary Storage Space in the drive pool of 10GB and I configured the drive with Simple resiliency level and 9 columns so that it will use all the disks in the pool to generate as much heat in the drives and on the controller as possible.
I ran three tests, 4K block 50% Read, 64K block 50% Read and lastly 256KB block 50% Read. I ran the test for minutes and visiting the garage to look at the server in the rack while this was happening, I was greeted to an interesting light show on the drive access indicator lights. After ten minutes of the sustained I/O, nothing bad happened so I decided to stop the test. Whilst I want to fix any issues, I don’t want to burn out any drives in the process.
Conclusion
At the moment, I’m really none the wiser as to the actual cause of the problem but I am still in part convinced that it is related to the RAID controller overheating. The increased baseline fan speed should hopefully help with this by increasing the CFM of airflow in the chassis to cool the controller. I’m going to be leaving the server be now until I hear from LSI with the results from their data collection. If LSI come up with something useful then great. If LSI aren’t able to come up with anything then I will probably run another set of ioMeter tests but let it run for a longer period to really try and saturate some heat into the controller.
With any luck, I won’t see the problems again and if I do, at least I’m prepared to capture the dump files and understand what’s happening.